Tutorial
SQLite vs MySQL vs PostgreSQL: A Comparison Of Relational Database Management Systems

Introduction
The relational data model, which organizes data in tables of rows and columns, predominates in database management tools. Today there are other data models, including NoSQL and NewSQL, but relational database management systems (RDBMSs) remain dominant for storing and managing data worldwide.
This article compares and contrasts three of the most widely implemented open-source RDBMSs: SQLite, MySQL, and PostgreSQL. Specifically, it will explore the data types that each RDBMS uses, their advantages and disadvantages, and situations where they are best optimized.
A Bit About Database Management Systems
Databases are logically modelled clusters of information, or data. A database management system (DBMS), on the other hand, is a computer program that interacts with a database. A DBMS allows you to control access to a database, write data, run queries, and perform any other tasks related to database management.
Although database management systems are often referred to as “databases,” the two terms are not interchangeable. A database can be any collection of data, not just one stored on a computer. In contrast, a DBMS specifically refers to the software that allows you to interact with a database.
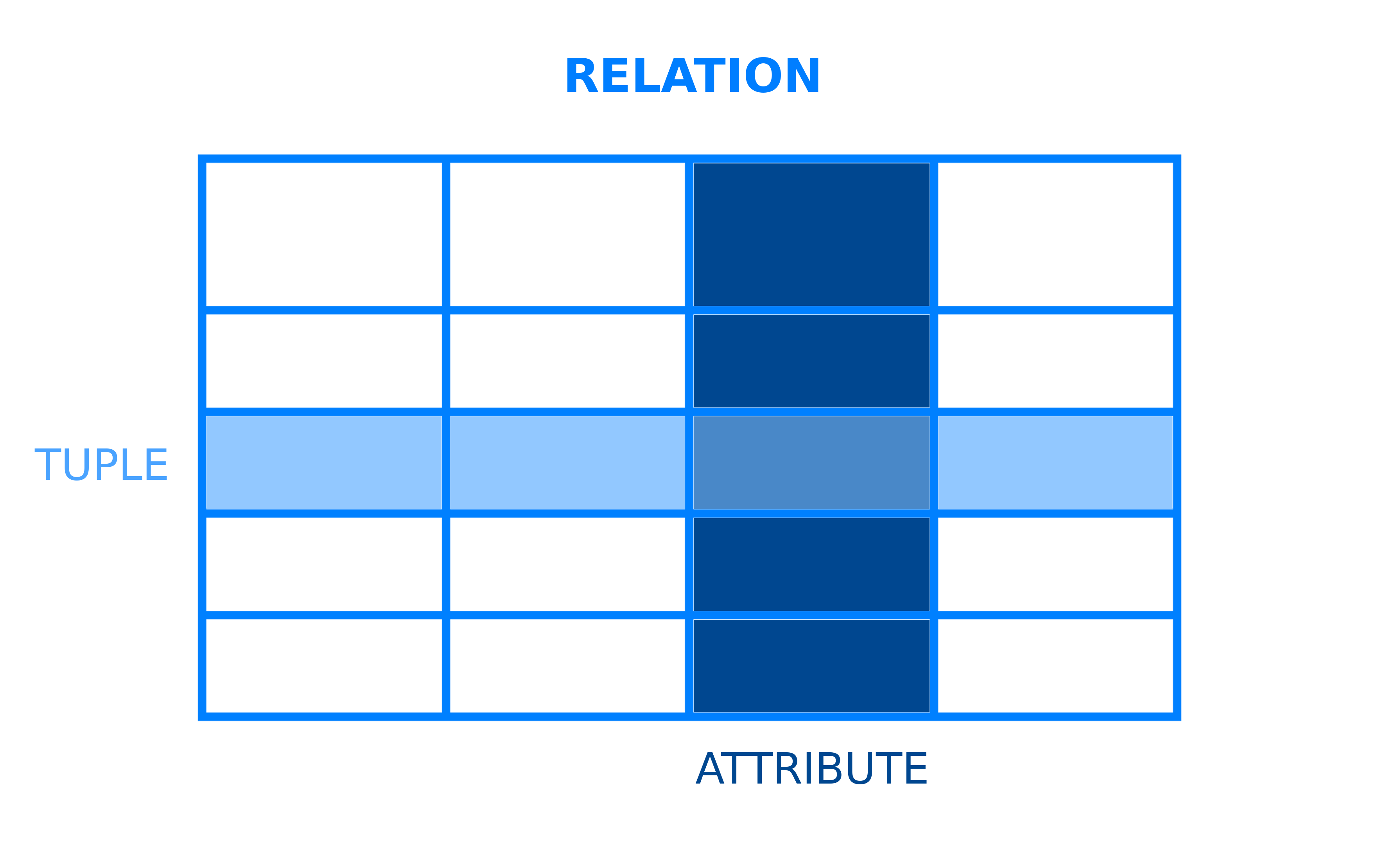
All database management systems have an underlying model that structures how data is stored and accessed. A relational database management system is a DBMS that employs the relational data model. In this relational model, data is organized into tables. Tables, in the context of RDBMSs, are more formally referred to as relations. A relation is a set of tuples, which are the rows in a table, and each tuple shares a set of attributes, which are the columns in a table:
Most relational databases use structured query language (SQL) to manage and query data. However, many RDBMSs use their own particular dialect of SQL, which may have certain limitations or extensions. These extensions typically include extra features that allow users to perform more complex operations than they otherwise could with standard SQL.
Note: The term “standard SQL” comes up several times throughout this guide. SQL standards are jointly maintained by the American National Standards Institute (ANSI), the International Organization for Standardization (ISO), and the International Electrotechnical Commission (IEC). Whenever this article mentions “standard SQL” or “the SQL standard,” it’s referring to the current version of the SQL standard published by these bodies.
It should be noted that the full SQL standard is large and complex: full core SQL:2011 compliance requires 179 features. Because of this, most RDBMSs don’t support the entire standard, although some do come closer to full compliance than others.
Data Types and Constraints
Each column is assigned a data type which dictates what kind of entries are allowed in that column. Different RDBMSs implement different data types, which aren’t always directly interchangeable. Some common data types include dates, strings, integers, and Booleans.
Storing integers in a database is more nuanced than putting numbers in a table. Numeric data types can either be signed, meaning they can represent both positive and negative numbers, or unsigned, which means they can only represent positive numbers. For example, MySQL’s tinyint data type can hold 8 bits of data, which equates to 256 possible values. The signed range of this data type is from -128 to 127, while the unsigned range is from 0 to 255.
Being able to control what data is allowed into a database is important. Sometimes, a database administrator will impose a constraint on a table to limit what values can be entered into it. A constraint typically applies to one particular column, but some constraints can also apply to an entire table. Here are some constraints that are commonly used in SQL:
UNIQUE: Applying this constraint to a column ensures that no two entries in that column are identical.NOT NULL: This constraint ensures that a column doesn’t have anyNULLentries.PRIMARY KEY: A combination ofUNIQUEandNOT NULL, thePRIMARY KEYconstraint ensures that no entry in the column isNULLand that every entry is distinct.FOREIGN KEY: AFOREIGN KEYis a column in one table that refers to thePRIMARY KEYof another table. This constraint is used to link two tables together. Entries to theFOREIGN KEYcolumn must already exist in the parentPRIMARY KEYcolumn for the write process to succeed.CHECK: This constraint limits the range of values that can be entered into a column. For example, if your application is intended only for residents of Alaska, you could add aCHECKconstraint on a ZIP code column to only allow entries between 99501 and 99950.
If you’d like to learn more about database management systems, check out our article on A Comparison of NoSQL Database Management Systems and Models.
Now that we’ve covered relational database management systems generally, let’s move onto the first of the three open-source relational databases this article will cover: SQLite.
SQLite
SQLite is a self-contained, file-based, and fully open-source RDBMS known for its portability, reliability, and strong performance even in low-memory environments. Its transactions are ACID-compliant, even in cases where the system crashes or undergoes a power outage.
The SQLite project’s website describes it as a “serverless” database. Most relational database engines are implemented as a server process in which programs communicate with the host server through an interprocess communication that relays requests. In contrast, SQLite allows any process that accesses the database to read and write to the database disk file directly. This simplifies SQLite’s setup process, since it eliminates any need to configure a server process. Likewise, there’s no configuration necessary for programs that will use the SQLite database: all they need is access to the disk.
SQLite is free and open-source software, and no special license is required to use it. However, the project does offer several extensions — each for a one-time fee — that help with compression and encryption. Additionally, the project offers various commercial support packages, each for an annual fee.
SQLite’s Supported Data Types
SQLite allows a variety of data types, organized into the following storage classes:
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
In the context of SQLite, the terms “storage class” and “data type” are considered interchangeable. If you’d like to learn more about SQLite’s data types and SQLite type affinity, check out SQLite’s official documentation on the subject.
Advantages of SQLite
- Small footprint: As its name implies, the SQLite library is very lightweight. Although the space it uses varies depending on the system where it’s installed, it can take up less than 600KiB of space. Additionally, it’s fully self-contained, meaning there aren’t any external dependencies you have to install on your system for SQLite to work.
- User-friendly: SQLite is sometimes described as a “zero-configuration” database that’s ready for use out of the box. SQLite doesn’t run as a server process, which means that it never needs to be stopped, started, or restarted and doesn’t come with any configuration files that need to be managed. These features help to streamline the path from installing SQLite to integrating it with an application.
- Portable: Unlike other database management systems, which typically store data as a large batch of separate files, an entire SQLite database is stored in a single file. This file can be located anywhere in a directory hierarchy, and can be shared via removable media or file transfer protocol.
Disadvantages of SQLite
- Limited concurrency: Although multiple processes can access and query an SQLite database at the same time, only one process can make changes to the database at any given time. This means that while SQLite supports greater concurrency than most other embedded database management systems, it cannot support as much as client/server RDBMSs like MySQL or PostgreSQL.
- No user management: Database systems often come with support for users, or managed connections with predefined access privileges to the database and tables. Because SQLite reads and writes directly to an ordinary disk file, the only applicable access permissions are the typical access permissions of the underlying operating system. This makes SQLite a poor choice for applications that require multiple users with special access permissions.
- Security: A database engine that uses a server can, in some instances, provide better protection from bugs in the client application than a serverless database like SQLite. For example, stray pointers in a client cannot corrupt memory on the server. Also, because a server is a single persistent process, a client-server database can control data access with more precision than a serverless database. This allows for more fine-grained locking and better concurrency.
When To Use SQLite
- Embedded applications: SQLite is a great choice of database for applications that need portability and don’t require future expansion. Examples include single-user local applications, mobile applications, or games.
- Disk access replacement: In cases where an application needs to read and write files to disk directly, it can be beneficial to use SQLite for the additional functionality and simplicity that comes with using SQL.
- Testing: For many applications it can be overkill to test their functionality with a DBMS that uses an additional server process. SQLite has an in-memory mode which can be used to run tests quickly without the overhead of actual database operations, making it an ideal choice for testing.
When Not To Use SQLite
- Working with lots of data: SQLite can technically support a database up to 140TB in size, as long as the disk drive and file system also support the database’s size requirements. However, the SQLite website recommends that any database approaching 1TB be housed on a centralized client-server database, as an SQLite database of that size or larger would be difficult to manage.
- High write volumes: SQLite allows only one write operation to take place at any given time, which significantly limits its throughput. If your application requires lots of write operations or multiple concurrent writers, SQLite may not be adequate for your needs.
- Network access is required: Because SQLite is a serverless database, it doesn’t provide direct network access to its data. This access is built into the application. If the data in SQLite is located on a separate machine from the application, it will require a high bandwidth engine-to-disk link across the network. This is an expensive, inefficient solution, and in such cases a client-server DBMS may be a better choice.
MySQL
According to the DB-Engines Ranking, MySQL has been the most popular open-source RDBMS since the site began tracking database popularity in 2012. It is a feature-rich product that powers many of the world’s largest websites and applications, including Twitter, Facebook, Netflix, and Spotify. Getting started with MySQL is relatively straightforward, thanks in large part to its exhaustive documentation and large community of developers, as well as the abundance of MySQL-related resources online.
MySQL was designed for speed and reliability, at the expense of full adherence to standard SQL. The MySQL developers continually work towards closer adherence to standard SQL, but it still lags behind other SQL implementations. It does, however, come with various SQL modes and extensions that bring it closer to compliance.
Unlike applications using SQLite, applications using a MySQL database access it through a separate daemon process. Because the server process stands between the database and other applications, it allows for greater control over who has access to the database.
MySQL has inspired a wealth of third-party applications, tools, and integrated libraries that extend its functionality and help make it easier to work with. Some of the more widely-used of these third-party tools are phpMyAdmin, DBeaver, and HeidiSQL.
MySQL’s Supported Data Types
MySQL’s data types can be organized into three broad categories: numeric types, date and time types, and string types.
Numeric types:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
Date and time types:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
String types:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 - 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 - 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 - 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 - 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 - 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 - 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 - 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 - 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
Advantages of MySQL
- Popularity and ease of use: As one of the world’s most popular database systems, there’s no shortage of database administrators who have experience working with MySQL. Likewise, there’s an abundance of documentation in print and online on how to install and manage a MySQL database. This includes a number of third-party tools — such as phpMyAdmin — that aim to simplify the process of getting started with the database.
- Security: MySQL comes installed with a script that helps you to improve the security of your database by setting the installation’s password security level, defining a password for the root user, removing anonymous accounts, and removing test databases that are, by default, accessible to all users. Also, unlike SQLite, MySQL does support user management and allows you to grant access privileges on a user-by-user basis.
- Speed: By choosing not to implement certain features of SQL, the MySQL developers were able to prioritize speed. While more recent benchmark tests show that other RDBMSs like PostgreSQL can match or at least come close to MySQL in terms of speed, MySQL still holds a reputation as an exceedingly fast database solution.
- Replication: MySQL supports a number of different types of replication, which is the practice of sharing information across two or more hosts to help improve reliability, availability, and fault-tolerance. This is helpful for setting up a database backup solution or horizontally scaling one’s database.
Disadvantages of MySQL
- Known limitations: Because MySQL was designed for speed and ease of use rather than full SQL compliance, it comes with certain functional limitations. For example, it lacks support for
FULL JOINclauses. - Licensing and proprietary features: MySQL is dual-licensed software, with a free and open-source community edition licensed under GPLv2 and several paid commercial editions released under proprietary licenses. Because of this, some features and plugins are only available for the proprietary editions.
- Slowed development: Since the MySQL project was acquired by Sun Microsystems in 2008, and later by Oracle Corporation in 2009, there have been complaints from users that the development process for the DBMS has slowed down significantly, as the community no longer has the agency to quickly react to problems and implement changes.
When To Use MySQL
- Distributed operations: MySQL’s replication support makes it a great choice for distributed database setups like primary-secondary or primary-primary architectures.
- Websites and web applications: MySQL powers many websites and applications across the internet. This is, in large part, thanks to how easy it is to install and set up a MySQL database, as well as its overall speed and scalability in the long run.
- Expected future growth: MySQL’s replication support can help facilitate horizontal scaling. Additionally, it’s a relatively straightforward process to upgrade to a commercial MySQL product, like MySQL Cluster, which supports automatic sharding, another horizontal scaling process.
When Not To Use MySQL
- SQL compliance is necessary: Since MySQL does not try to implement the full SQL standard, this tool is not completely SQL compliant. If complete or even near-complete SQL compliance is a must for your use case, you may want to use a more fully compliant DBMS.
- Concurrency and large data volumes: Although MySQL generally performs well with read-heavy operations, concurrent read-writes can be problematic. If your application will have many users writing data to it at once, another RDBMS like PostgreSQL might be a better choice of database.
PostgreSQL
PostgreSQL, also known as Postgres, bills itself as “the most advanced open-source relational database in the world.” It was created with the goal of being highly extensible and standards compliant. PostgreSQL is an object-relational database, meaning that although it’s primarily a relational database it also includes features — like table inheritance and function overloading — that are more often associated with object databases.
Postgres is capable of efficiently handling multiple tasks at the same time, a characteristic known as concurrency. It achieves this without read locks thanks to its implementation of Multiversion Concurrency Control (MVCC), which ensures the atomicity, consistency, isolation, and durability of its transactions, also known as ACID compliance.
PostgreSQL isn’t as widely used as MySQL, but there are still a number of third-party tools and libraries designed to simplify working with with PostgreSQL, including pgAdmin and Postbird.
PostgreSQL’s Supported Data Types
PostgreSQL supports numeric, string, and date and time data types like MySQL. In addition, it supports data types for geometric shapes, network addresses, bit strings, text searches, and JSON entries, as well as several idiosyncratic data types.
Numeric types:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
Character types:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Date and time types:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Geometric types:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Network address types:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Bit string types:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Text search types:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
JSON types:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Other data types:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Advantages of PostgreSQL
- SQL compliance: More so than SQLite or MySQL, PostgreSQL aims to closely adhere to SQL standards. According to the official PostgreSQL documentation, PostgreSQL supports 160 out of the 179 features required for full core SQL:2011 compliance, in addition to a long list of optional features.
- Open-source and community-driven: A fully open-source project, PostgreSQL’s source code is developed by a large and devoted community. Similarly, the Postgres community maintains and contributes to numerous online resources that describe how to work with the DBMS, including the official documentation, the PostgreSQL wiki, and various online forums.
- Extensible: Users can extend PostgreSQL programmatically and on the fly through its catalog-driven operation and its use of dynamic loading. One can designate an object code file, such as a shared library, and PostgreSQL will load it as necessary.
Disadvantages of PostgreSQL
- Memory performance: For every new client connection, PostgreSQL forks a new process. Each new process is allocated about 10MB of memory, which can add up quickly for databases with lots of connections. Accordingly, for simple read-heavy operations, PostgreSQL is typically less performant than other RDBMSs, like MySQL.
- Popularity: Although more widely used in recent years, PostgreSQL has historically lagged behind MySQL in terms of popularity. One consequence of this is that there are still fewer third-party tools that can help manage a PostgreSQL database. Similarly, there aren’t as many database administrators with experience managing a Postgres database compared to those with MySQL experience.
When To Use PostgreSQL
- Data integrity is important: PostgreSQL has been fully ACID-compliant since 2001 and implements multiversion currency control to ensure that data remains consistent, making it a strong choice of RDBMS when data integrity is critical.
- Integration with other tools: PostgreSQL is compatible with a wide array of programming languages and platforms. This means that if you ever need to migrate your database to another operating system or integrate it with a specific tool, it will likely be easier with a PostgreSQL database than with another DBMS.
- Complex operations: Postgres supports query plans that can leverage multiple CPUs in order to answer queries with greater speed. This, coupled with its strong support for multiple concurrent writers, makes it a great choice for complex operations like data warehousing and online transaction processing.
When Not To Use PostgreSQL
- Speed is imperative: At the expense of speed, PostgreSQL was designed with extensibility and compatibility in mind. If your project requires the fastest read operations possible, PostgreSQL may not be the best choice of DBMS.
- Simple setups: Because of its large feature set and strong adherence to standard SQL, Postgres can be overkill for simple database setups. For read-heavy operations where speed is required, MySQL is typically a more practical choice.
- Complex replication: Although PostgreSQL does provide strong support for replication, it’s still a relatively new feature. Some configurations — like a primary-primary architecture — are only possible with extensions. Replication is a more mature feature on MySQL and many users see MySQL’s replication to be easier to implement, particularly for those who lack the requisite database and system administration experience.
Conclusion
Today, SQLite, MySQL, and PostgreSQL are the three most popular open-source relational database management systems in the world. Each has its own unique features and limitations, and excels in particular scenarios. There are quite a few variables at play when deciding on an RDBMS, and the choice is rarely as simple as picking the fastest one or the one with the most features. The next time you’re in need of a relational database solution, be sure to research these and other tools in depth to find the one that best suits your needs.
If you’d like to learn more about SQL and how to use it to manage a relational database, we encourage you to refer to our How To Manage an SQL Database cheat sheet. On the other hand, if you’d like to learn about non-relational (or NoSQL) databases, check out our Comparison Of NoSQL Database Management Systems.
References
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Getting Started With Cloud Computing
This curriculum introduces open-source cloud computing to a general audience along with the skills necessary to deploy applications and websites securely to the cloud.

author
author
Manager, Developer Education
Technical Writer @ DigitalOcean
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Featured on Community

Get our biweekly newsletter
Sign up for Infrastructure as a Newsletter.

Hollie's Hub for Good
Working on improving health and education, reducing inequality, and spurring economic growth? We'd like to help.

Become a contributor
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

There’s a whole lot of things missing from the PostgreSQL benefits section. Just off the top of my head:
Full Text Search
PG has full text search capabilities that rival standalone dedicated search engines like Solr, Sphinx, and Elastic Search. The full text search that exists in MySQL is scary by comparison. If your are only searching data in the database, its the way do go. You don’t have to setup and manage another system. You don’t have to worry about data syncing issues either or encoding issues transitioning your data from PG to another search engine. It has multiple dictionaries that you can implement all over the place. You can even add your own, weight searchable parts, etc.
Multi Index Queries
This is big and ties into the previous one. By default, PostgreSQL does multi-index queries so when you’re creating an index you just add them for individual columns that you will need to search on. You don’t need to create an index over multiple fields unless it’s there to maintain uniqueness across multiple fields.
Combined with the built in full text search, that means that you can just add the full text search to any where clause and all of the indexes for other items will be hit as well.
Custom data types
PG is extensible and allows the creation of custom data types as well as having 2 types of indexes built for working with those custom data types. JSON and hstore were mentioned earlier and they are the result of this. There are many other custom data types (XML, ISBN, etc) to handle just about any need that you could have…and since PG handles multi-index queries…well, that’s awesome.
Functions are amazing
Database functions are great for use in queries or manipulating data that comes back, but PostgreSQL takes them to another level. You can you create an index with the results of a function that will automatically get used when the matching function is used in a where clause. Things like a unique index on a lowercase username come to mind. This is extremely helpful if you’re working with XML too because you can’t index an XML file…but you can index the result of an XPATH function on the XML datatype.
Wasted space is TOASTed
TOAST is the compression layer behind PG’s TEXT field types. It automatically zip’s large data. I dropped a 2.2 mb XML file in and it stored in as 81 kb.
Stored procedures aren’t painful
You can write stored procedures in other languages including Python and Javascript. This makes putting logic that belongs in your database in there a whole lot simpler.
LISTEN/NOTIFY will change your life
Never have a long running process poll for changes to data again. Long running server processes can now hold a connection and let the database tell them when a change happened. These remove your dependence on framework “AFTER SAVE” hooks, which really comes in handy when you need to connect to your database with another language. If it changes in the database, it changes everywhere.
A few quick use cases for this:
PostGIS for Geospatial Data
Adds a bunch of custom datatypes and logic for dealing with geospatial data. Because you can do that with PostgreSQL.
Because of multi-index queries, this means that in one query you can search for basic where conditions, full text, and filter by geospatial parameters like distance. In ONE. DANG. QUERY.
This is off the top of my head. There’s a lot more.
The date-time type of MySQL doesn’t store the time zone. In PostrgeSQL, it does.
Please rename “Glossary” to “Table of Contents”
This comment has been deleted
As other’s have said JSON support in PostgreSQL is a huge benefit over other RDBMS. The fact that I can throw in a simple JSON object and then query against its property fields using a SQL query makes PostgreSQL immensely powerful.
“Unless you require absolute data integrity, ACID compliance or complex designs, PostgreSQL can be an over-kill for simple set-ups.”
People who don’t need those things probably have no business using a database at all. It’s shocking how many people think that the average self-hosted Wordpress site is actually dynamic and thus requires a database. The vast majority of things out there using a database are static sites with a silly, over-engineered backend.
Postgres JSON data type is a huge advantage over MySQL.
I would like to point out that the JSON and hstore datatypes in PostgreSQL aren’t mentioned, and are extremely useful.
I question the claim that MySQL is “The most popular and commonly used RDBMS”. It depends on what you mean by “popular and commonly used”, but SQLite is used almost everywhere these days. I honestly don’t know how to do anything on my computer or phone today that doesn’t use SQLite. It’s in iOS and Android, it’s in Firefox and Chrome, it’s in OS X (and used by every OS X application, indirectly, and several of them directly) and Linux. It’s used by Dropbox and Skype and Lightroom and Airbus and pretty much every major software company in the world.
MySQL is very popular for web apps, but SQLite is very popular for basically everything else.
Just joined D.O. because of this post. Great information for someone looking to get more familiar with databases. Thanks to everyone who commented as well.